Settings
Transcription
This page describes transcription settings: provider, local model, preferred language, fine-tuning dataset and privacy.
Objective
Choose the transcription engine, configure the local model, set the preferred language and manage fine-tuning datasets.
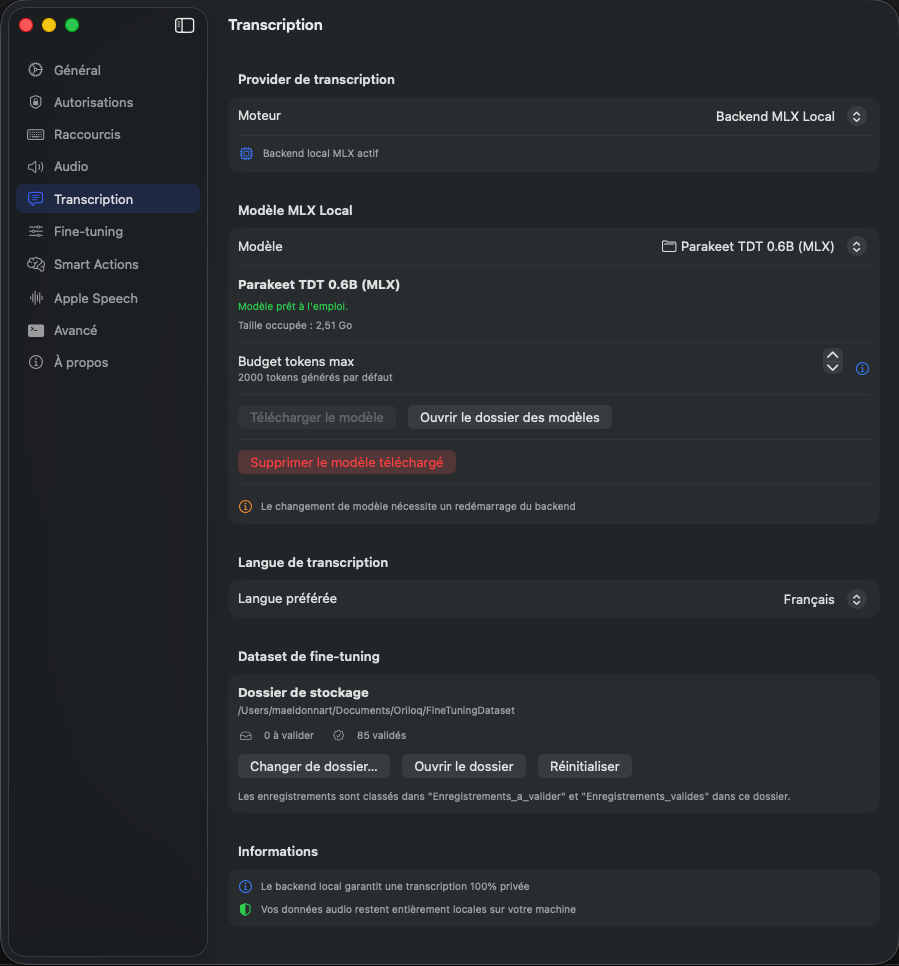
Transcription provider
Oriloq offers several transcription engines. Use the Engine dropdown to select the desired provider (e.g. Backend MLX Local). When a local backend is active, an indicator confirms its status.
Local MLX Model
Select the transcription model via the Model dropdown. When a model is ready, Oriloq displays its status (“Model ready to use”) along with the disk space it occupies. Adjust the Max token budget to limit the number of tokens generated per transcription. Click Open models folder to access the directory in Finder. If the model has not been downloaded yet, click Download model to fetch it. Use Delete downloaded model to free up disk space. Note: changing the model requires a backend restart.
Transcription language
Set the Preferred language via the dropdown to tell Oriloq which language you primarily dictate in. This setting helps the model optimize speech recognition for the chosen language.
Fine-tuning dataset
This section lets you manage the storage folder for recordings used to fine-tune the transcription model. Oriloq shows the number of recordings pending validation and validated. Use Change folder… to select a different location, Open folder to access it in Finder, or Reset to restore the default path. Recordings are organized into the “Enregistrements_a_valider” and “Enregistrements_valides” subfolders.
Cloud providers (optional)
Since version 1.0.6, two cloud engines are available directly in the model selector, without enabling developer mode:
- →ElevenLabs Scribe — cloud transcription with per-word timestamps, automatic punctuation correction and accurate alignment (1.0.7).
- →Mistral Voxtral — Mistral's cloud engine. A dedicated Voxtral language option is available higher in this section.
Cloud results come back as coherent plain text. You can re-transcribe the same capture locally at any time if you prefer not to rely on the cloud.
Voxtral streaming (beta)
Since version 1.0.11, the first settings for Voxtral streaming mode are available. This mode prepares real-time transcription as you speak, without waiting for the end of the audio segment. It is still in beta: use it for experimentation, and keep segment-based transcription for critical use cases.
Model memory management
Since version 1.0.11, an option lets you keep transcription models loaded in memory between dictations, for nearly instant launches. Unloading adapts automatically to your Mac's memory pressure: if the system needs RAM, Oriloq releases the model; otherwise, it stays ready.
A real-time memory usage indicator is available in the developer settings (since 1.0.6) to track the actual footprint.
Information
The local backend guarantees 100% private transcription: your audio data stays entirely local on your machine and is never sent to an external server.